Lecture notes from Natural Language Processing (by Michael Collins)
Tagging
Tagging: Strings to Tagged Sequences
Example 1: Part-of-speech Tagging (POS tags)

Tag each word in a sentence with its component name.
Example 2:Named Entity Recognition (NER)
Find and classify names in text.
To understand a role in a sentence.

Parsing
Focuses on relations between words.
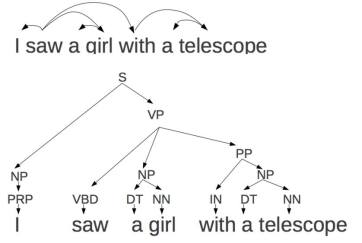
Why is NLP Hard? Ambiguity.
Let’s go back to the example.
“I saw a girl with a telescope.”
How do you understand the example: “I saw a girl, and the girl was with a telescope”, or “I used a telescope and saw a girl”.
Different structures in parsing lead to different interpretations.
Ambiguity also exits in semantic (meaning) level.
“They put money in the bank.” The word “bank” itself has more than one meanings. Did they bury the money into mud? Obviously, that’s not the case.
Ambiguity in discourse (multi-clause) level. For example, it should be able to understand whom the word “he” or “she” is referring to.
Language Modeling
Finite vocabulary,
An infinite set of strings, like any combinations of vocabulary.

The Language Modeling Problem
– Training samples in English
– Learn a probability distribution p:
(p is the output when the input is a given sentence.)

Markov Processes
A sequence of random variables 
The model (a joint probabilit), 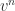

First-Order Markov Processes
The current state of one random variable, only depends on its previous one, has nothing to do with the ones before the previous one.
So we have:
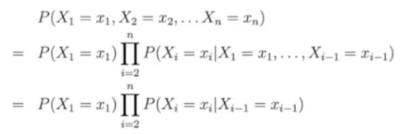
It’s reasonable to change to the thrid line, because of the Markov Assumption.
Second-Order Markov Processes:
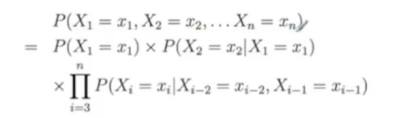
The current state now is dependent on its previous two variables’ states.
More info about about Markov Assumption, go here.
Trigram Language Models
– A finite set V
– A parameter 

The TLM:
where 
An example:
Given a sentence: “the dog barks STOP”. We will have a model like this:

Four words (including the STOP tag), we will have the same number of probability to sum product. And at each time, we focus (condition) on two previous words. So how do we know the probabilities? We need an estimation.
Estimation of Trigram Model
A natural estimate (maximum likelihood estimate):
By count only on the appearance of the trigrams, finally get the maximum likelihood estimation of them.
References:
https://class.coursera.org/nlangp-001/lecture

your detailed note is just awesome. While there exists some minor mistakes, i.e., `$q(w|,u,v)$`, `(a joint probability)` .
LikeLike
Thanks for the check!
I’ll try to improve my writing wow
LikeLike
Your blog is quite helpful for a beginner like me in explaning NLP
LikeLike
Thanks:)
LikeLike