(A new learner! Leave comments if you find any mistakes please!)
How do we present a word? In TensorFlow, everything, yes everything, flows into the graph, is a tensor. For example, the famous word2vec model is used for learning vector representations of words.
Representation
It is natural that we will use RGB channels to represent an image pixel by pixel. So we will represent an image in a huge tensor, contains those channels with proper values for colors. What about other signals, e.p. audios and human movements. They all can be seen as functions on time-series. We can represent them as a tensor with the cleaned true values directly. When it comes to words, we want to find a similar way to represent them as well.
One goal for Deep Learning is to learn representations (called representation learning). That is, let’s find some ways to represent something. For example, suppose we are going to build an image search engine. If we find out a way to transfer every image into a value, e.p, image A is 3, image B is 5, image C is 300. Closing value means similar images. When we put image A as a query, we will find image B instead of image C, because B is similar. Now we are representing images with real values, so you see how powerful it is!
Sparse Text Representation
Bag-of-Words (BoW) model. Consider the task to classify documents. The core is to find out how similar two documents are, then you could use algorithms like K-means to find out. We would first know how many words in our corpus. Then we could represent a document based on how many time each word in corpus occurs as a vector. Finally, we would have an occurrence matrix. Another process contains stop-words removing, TF-IDF, etc. However, the matrix will be very sparse. If you have a universal corpus which has words from all domains, a domain-specific document would contain only a small part of the huge corpus. That means you will have lots of zeros in the vector of occurrence. The sparse problem could be a motivation for word representation.
Word Representation
Usually to represent a word, we will consider its context. There is a classic example of thinking of:
Sentence A “I use TensorFlow to study Deep Learning”.
Sentence B “Lee uses Caffe to study Deep Learning”.
We have reasons to believe that “TensorFlow” and “Caffe” have similar meaning because they appearance in the same position and structure.
CBOW Understanding (repost part from a Chinese blog)
Predict a word w, given its context Context(w). So with word w, it is a positive sample, while other words are all negative samples. When given a positive sample 
It is simply a multiplication of all conditional probabilities of a target word, given the current context. So we wish to maximize it. Where,
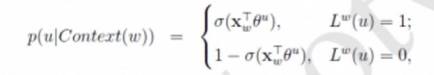

We define a “flag” function 


So the first part denotes the probability of the positive sample, while the second one denotes the probabilities of negative ones. We would like to maximize function g(w), which means we will maximize the value of 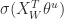
Keep in mind that the parameter 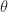

Skip-gram Model Understanding
In skip-gram, it is a reversed version of CBoW. So the task is we will The skip-gram Model is mainly based on negative sampling. Skip-gram and CBoW are somehow similar
Similar objective function can be found in the TF tutorial:
![]() Where we consider both positive and negative samples and try to maximise it, where we select k noise words from the negative samples. The function is scaled on the number k, not necessarily being the size of your whole vocabulary. In TensorFlow, this is called Noise-Contrastive Estimation (NCE) loss, where the single function would help you with the work: tf.nn.nce_loss().
Where we consider both positive and negative samples and try to maximise it, where we select k noise words from the negative samples. The function is scaled on the number k, not necessarily being the size of your whole vocabulary. In TensorFlow, this is called Noise-Contrastive Estimation (NCE) loss, where the single function would help you with the work: tf.nn.nce_loss().
(lol you will find that lots of keywords will lead you to a paper in Google TF tutorial)
T-SNE
A helpful method for you to visualize your high-dimensional data. If you are familiar with PCA, given a high-d vector, we could use 2-d or 3-d to represent it, which allows us to plot it in a proper low dimension. When the word embeddings are trained (it is usually a fixed-size set of vectors), we could use T-SNE to visualize the word clusters.

(A trained word embedding visualization from the Pride and Prejudice )
The trained embedding is ready to use for RNNs.
Hope this blog will help you understanding the TF tutorial in Word Representation.
For the implementation part, I will update part 2 as a new blog.

I found some useful information in your blog, it was awesome to read, thanks for sharing this great content to my vision, keep sharing.
For more related to Skip-Gram Model
LikeLike