Introduction
First introduced by Mikolov 1 in 2013, the word2vec is to learn distributed representations (word embeddings) when applying neural network. It is based on the distributed hypothesis that words occur in similar contexts (neighboring words) tend to have similar meanings. Two models here: cbow ( continuous bag of words) where we use a bag of words to predict a target word and skip-gram where we use one word to predict its neighbors. For more, although not highly recommended, have a look at TensorFlow tutorial here.
After this idea is proved to be effective and helpful, say, you can easily cluster and find similar words in a huge corpus, people then began thinking further: is it possible to have a higher level of representation on sentences, paragraphs or even documents.
One idea is we can first use the word embeddings to represent each word in a sentence, then apply a simple average pooling approach where the generated document vector is actually a centroid of all words in the space 2. The popular idea is we following the similar idea on traning the word2vec to learn distributed representations for pieces of texts as an unsupervised method [3,4].
Models
Similarly, there are two models in doc2vec: dbow and dm.
dbow (distributed bag of words)
It is a simpler model that ignores word order and training stage is quicker. The model uses no-local context/neighboring words in predictions. You see it is not considering the order of the words. From the paper 4, the figure below shows dbow.

In Gensim, you will code like this:
model = gensim.models.Doc2Vec(documents,dm = 0, alpha=0.1, size= 20, min_alpha=0.025)
Set dm to be 0. If you print out word embeddings at each epoch, you will notice they are not updating. From the graph above, we may guess that we have only paragraph embeddings updated during backpropagation.
dm (distributed memory)
We treat the paragraph as an extra word. Then it is concatenated/averaged with local context word vectors when making predictions. During training, both paragraph and word embeddings are updated. It calls for more computation and complexity.

In Gensim, set the dm to be 1(by default):
model = gensim.models.Doc2Vec(documents,dm = 1, alpha=0.1, size= 20, min_alpha=0.025)
Print out word embeddings at each epoch, you will notice they are updating.
More detailed: we treat each document as an extra word; doc ID/ paragraph ID is represented as one-hot vector; documents are also embedded into continuous vector space.
Example with Gensim
Gensim provides lots of models like LDA, word2vec and doc2vec. While I found some of the example codes on a tutorial is based on long and huge projects (like they trained on English Wiki corpus lol), here I give few lines of codes to show how to start playing with doc2vec.
First, you need is a list of txt files that you want to try the simple code on. I have a list of txt files under the folder named docs. Two .py files in total: load.py for reading and cleaning data and doc2vectest.py for running doc2vec model.
load.py
import gensim
import os
import re
from nltk.tokenize import RegexpTokenizer
from stop_words import get_stop_words
from nltk.stem.porter import PorterStemmer
from gensim.models.doc2vec import TaggedDocument
def get_doc_list(folder_name):
doc_list = []
file_list = [folder_name+'/'+name for name in os.listdir(folder_name) if name.endswith('txt')]
for file in file_list:
st = open(file,'r').read()
doc_list.append(st)
print ('Found %s documents under the dir %s .....'%(len(file_list),folder_name))
return doc_list
def get_doc(folder_name):
doc_list = get_doc_list(folder_name)
tokenizer = RegexpTokenizer(r'\w+')
en_stop = get_stop_words('en')
p_stemmer = PorterStemmer()
taggeddoc = []
texts = []
for index,i in enumerate(doc_list):
# for tagged doc
wordslist = []
tagslist = []
# clean and tokenize document string
raw = i.lower()
tokens = tokenizer.tokenize(raw)
# remove stop words from tokens
stopped_tokens = [i for i in tokens if not i in en_stop]
# remove numbers
number_tokens = [re.sub(r'[\d]', ' ', i) for i in stopped_tokens]
number_tokens = ' '.join(number_tokens).split()
# stem tokens
stemmed_tokens = [p_stemmer.stem(i) for i in number_tokens]
# remove empty
length_tokens = [i for i in stemmed_tokens if len(i) > 1]
# add tokens to list
texts.append(length_tokens)
td = TaggedDocument(gensim.utils.to_unicode(str.encode(' '.join(stemmed_tokens))).split(),str(index))
# for later versions, you may want to use: td = TaggedDocument(gensim.utils.to_unicode(str.encode(' '.join(stemmed_tokens))).split(),[str(index)])
taggeddoc.append(td)
return taggeddoc
The method get_doc_list is used for loading all txt files under a directory, it returns a list of strings. If you have 4 txts, then the length of the list will be 4.
The method get_doc is mainly for cleaning strings then port the data into some format that doc2vec can use. After we get the long string for each txt, we preprocess it by tokenizing, removing stopwords and numbers, stemming(that is if you have “supply” and “supplies”, then they will convert to “suppli”). You can change and add more filters in this step.
From the tutorial given by Radim 5, The TaggedDocument (used to be LabeledSentence) is like this:
sentence = TaggedDocument(words=[u'some', u'words', u'here'], tags=[u'SENT_1'])
You need to pass in a Unicode format list of words and the tags of the document (we agree here a document is a collection of words). Normally we give one tag for each document, but you can still assign more than one. In my experiment, I just give a unique id to each doc as their tag.I tried with int but got an error! The str.encode(somestringhere) method helps you convert a string to the unicode-format. Method get_doc returns a list of TaggedDocument objects.
doc2vectest.py
import gensim
import load
documents = load.get_doc('docs')
print ('Data Loading finished')
print (len(documents),type(documents))
# build the model
model = gensim.models.Doc2Vec(documents, dm = 0, alpha=0.025, size= 20, min_alpha=0.025, min_count=0)
# start training
for epoch in range(200):
if epoch % 20 == 0:
print ('Now training epoch %s'%epoch)
model.train(documents)
model.alpha -= 0.002 # decrease the learning rate
model.min_alpha = model.alpha # fix the learning rate, no decay
# shows the similar words
print (model.most_similar('suppli'))
# shows the learnt embedding
print (model['suppli'])
# shows the similar docs with id = 2
print (model.docvecs.most_similar(str(2)))
After loading the documents, we are able to build a doc2vec model. Yes, just one line.
We are able to pass in documents and assign hyper-parameters. You can find a full version about the methods here 6. If the dm = 0, then we are training a dbow model. The size = 20 defines the dimension of doc vectors. If we initialize by passing in documents here, then we do not need to build vocabulary, it is done by itself.
You can train it for a number of epochs by changing the learning rate (alpha).
After some time, let’s print some results. Do remember when we train doc2vec, we can get word embeddings and also document similarities, and even label representations!
Here I printed most similar words of “suppli”:
>>model.most_similar('suppli')
[('gorski', 0.7319533824920654), ('ensur', 0.7222224473953247), ('beyond', 0.718737006187439), ('d', 0.6974059343338013), ('sociedad', 0.6583201885223389), ('particularli', 0.6544623374938965), ('lvg', 0.644609808921814), ('sal', 0.6434764862060547), ('measur', 0.6433277130126953), ('livneh', 0.6426206827163696)].
And let’s see how the word “suppli” is represented (a 20-d vector):
>>model['suppli'] [ 0.00780776 -0.02093589 -0.00954595 0.01870585 -0.0185861 0.0023135 0.00341994 0.00175795 0.01479601 0.01020735 0.02441289 0.01075038 0.00807728 0.0213691 0.01130075 0.01297983 0.01369582 -0.01174711 -0.00518298 -0.00057144]
Then the similarity/ distance between the document with ID 2 and the rest:
>>model.docvecs.most_similar(str(2))
[('1', 0.44029974937438965), ('0', -0.044562749564647675), ('3', -0.048865705728530884), ('6', -0.08216284960508347), ('9', -0.15016411244869232), ('5', -0.16429446637630463), ('4', -0.1840556114912033), ('8', -0.21571332216262817), ('7', -0.23153537511825562)]
You can save both word embeddings and document/paragraph embeddings:
model.save('save/trained.model')
model.save_word2vec_format('save/trained.word2vec')
When you want to use the model:
# load the word2vec
word2vec = gensim.models.Doc2Vec.load_word2vec_format('save/trained.word2vec')
print (word2vec['good'])
# load the doc2vec
model = gensim.models.Doc2Vec.load('save/trained.model')
docvecs = model.docvecs
# print (docvecs[str(3)])
They will print out the vectors for you.
Plot
We can simply get those word embeddings, and plot them (as done in the word2vec). Here a simple PCA() method was used first, then we take some of the words to plot. After PCA(), we reduced dimension of a word to 2.
def plotWords():
#get model, we use w2v only
w2v,d2v=useModel()
words_np = []
#a list of labels (words)
words_label = []
for word in w2v.vocab.keys():
words_np.append(w2v[word])
words_label.append(word)
print('Added %s words. Shape %s'%(len(words_np),np.shape(words_np)))
pca = decomposition.PCA(n_components=2)
pca.fit(words_np)
reduced= pca.transform(words_np)
# plt.plot(pca.explained_variance_ratio_)
for index,vec in enumerate(reduced):
# print ('%s %s'%(words_label[index],vec))
if index <100:
x,y=vec[0],vec[1]
plt.scatter(x,y)
plt.annotate(words_label[index],xy=(x,y))
plt.show()
We will plot something like this:
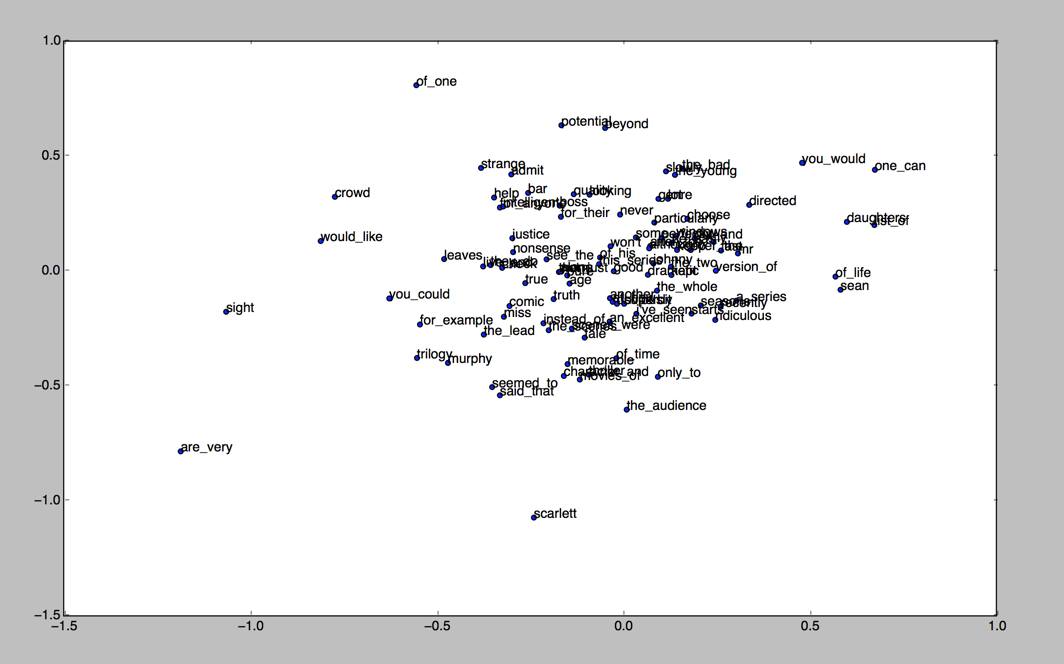
References:

Hello. I use your load.py script. But I got an error.
length_tokens = [i for i in stemmed_tokens if len(i) &gt;1]
Python show that invalid syntax “len(i) &gt;1”
How can I solve?
Thanks
LikeLike
Hi,
This part “len(i) >1” should be “len(i) > 1”. I’ve updated. Because every time I copy the code to wordpress, some characters would be changed, I need to revise manually. wow
LikeLike
Thanks
LikeLike
Could you comment on the pros and cons of applying the word stemmer in this case, what is the tradeoff?
– Thanks for this article, is a great starting point for learning to apply embeddings.
LikeLike
Hi Adrian, according to my experiments, if applying stemming, the average accuracy would go lower. The reason is we are losing too much infomation, for example, in these two cases “a study shows…” (a noun), “he studied …”(a verb) , both of the keywords will become “studi”, a same word embedding. But generally, a noun and a verb should not be the same in our embeddings.
LikeLike
Hi Irene, i love this post about doc2vec because it helped me to progess. However, i am wondering how to update a pre-trained model on which I did look for an answer and found that after loading the model i have to set the parameter update in build_vocab to true and in the fro loop when training is being in progress. But which method should i call train or infer_vector, and should is also call update_weights because i did and it did sound logic to me.
LikeLike
Hi there, sorry I did not try to load pre-trained embeddings with Gensim. If the pretrained embeddings were by Gensim, then it is easy. Because I always using Gensim to pre-train, then I load them by TensorFlow and update the weights. You might want to have a look of this post:https://ireneli.eu/2017/01/17/tensorflow-07-word-embeddings-2-loading-pre-trained-vectors/
LikeLike
Hi I was wondering if all the code was here (or is it on github?). I am not sure where the referecne to useModel() is in the plot of PCA. Nice description of doc2vec, clearly explained.
LikeLike
Hi,
Sorry, the full version was not on github. Some part of the codes were about my research so did not make them public 😀
LikeLiked by 1 person
Hi Irene!
I’m on Python 3 (Windows) and get the following error when trying to run doc2vectest.py:
UnicodeDecodeError: ‘charmap’ codec can’t decode byte 0x9d in position 183: character maps to
(Thanks for the tutorial btw 🙂 )
LikeLike
PS – In Py2.7 I get:
UnicodeDecodeError: ‘ascii’ codec can’t decode byte 0xe2 in position 0: ordinal not in range(128)
LikeLike
Hi Dee,
Hmmm, my initial guess is the Gensim version issue? The post was written last summer, now Gensim has very new versions. Or maybe Python3 with Gensim issues when you read files, but plz try:
>>file = open(filename, encoding=”utf8″)
LikeLike
Hi,
Thanks for the suggestion! I did the following:
>>st = open(file, encoding=”utf8″).read()
But unfortunately it didn’t work.
LikeLiked by 1 person
Hi, Irene,
thank you for your post, it’s helpful. I’m wondering how to apply your approach to document classification. I only have 5 categories and some hundred of document to train, and it is not possible to pre-trainned embeddings because of the very artificial vocabulary of the documents. The word order has to be considered. I’ll appreciate any help. Thank you!
LikeLike
Hi,
Thanks for the comment on the post.
Well for document classification, I do not suggest you to use doc2vec. I did try doc2vec on my works to do sentence level classification, but it is worse than a Convolutional Neural Network. Please find more on my paper here for a quick view. The paper is still working on a sentence level classification.
For your issue, you need to go even higher level: from sentences to documents. The state of the art method I believe is a hierarchical model. I am trying with this. In brief, you need to train word embeddings as input, then the model would train sentence representations and document representations. By adding attention-based mechanism (I personally think it is good at longer sequences), better results could be achieved. You can search code for that paper, the authors did not publish the code but there are people implemented it already.
Thank you.
LikeLike
thank you very much for your anwer Irene.
Actually, my “documents” are a kind of sentences. Here you are an example:
1dMfLpLde 1dLfLpMde 1dLfLpLde 1dLfHpLgh 1dHfLpLde 1dLfMpLah 1dLfMpLth 1dLfHpLgh 1dLfMpLah 1dLfLpLde 1dLfHpLgl 1dLfHpLgh 1dMfLpMde 1dHfLpLde 1dLfMpLbl 1dLfHpLgh 1dLfLpLde 1dLfHpMgh 1dLfMpMbh 1dLfHpHgl 1dLfLpMde 1dLfHpMgh 1dLfHpMgh 1dLfMpLgl 1dMfLpMde 1dLfHpLgh 1dLfMpLbh 1dHfLpLde 1dLfHpLgl 1dLfLpMde 1dLfLpLde 1dLfHpLgh 1dLfMpLbl 1dLfHpLgh 1dLfMpLgl 1dLfHpLgh 1dLfMpLbh 1dLfHpLgh 1dLfHpMgl 1dLfMpLah 1dLfHpLgh 1dLfHpLgh
That is my strange sentence, or document! So we don’t need to distinguish sentence and document. The question is that the sequence of words is relevant, at least that is our intuition.., I’ll read your paper, thank you!
LikeLike
Hi,
Although I do not understand the data….at least you think the order matters, aka, you believe that the dependencies are important in the “sentences”. And the elements in the sequences could be treated as “words”. I think it is reasonable to apply any NLP technique. Feel free to try LSTM, etc. Thanks.
LikeLike
Hi Irene,
Thanks for post. Can you add few lines how to find the similar sentence? and also I didn’t find a way to print the ACTUAL similar sentence from model anywhere.
LikeLike
Hi Krishna, in practice we can use cosine similarity to measure the similarities. We have each sentence represented as a vector, so it is not hard to do so. You can find info here: http://blog.christianperone.com/2013/09/machine-learning-cosine-similarity-for-vector-space-models-part-iii/
Gensim has its own function to do this:https://radimrehurek.com/gensim/tut3.html
In my post I used only this line: model.docvecs.most_similar(str(2))
Hope this will help. Thanks.
LikeLike
Hi Irene,
Thank you so much for this post; I’ve been trying to figure out how document vectors work mathematically and this is the best explanation I’ve found so far. I was wondering if you could clarify some additional points:
— When you say “we treat each document as an extra word; doc ID/ paragraph ID is represented as one-hot vector; documents are also embedded into continuous vector space,” do you mean that two separate inputs are used to represent a document: both a one-hot vector and a continuous ID variable?
— If so, how are these pieces of information passed through the SGD algorithm? Are both the one-hot vector and continuous-scale ID tag passed in as input alongside their constituent word vector?
— When you say “We treat the paragraph as an extra word. Then it is concatenated/averaged with local context word vectors when making predictions,” does this concatenation happen before the word and/or document vectors are passed through the algorithm? In other words, do word and document vectors get passed though as separate inputs, or are they sort of “chunked” together into a single input?
Thanks again!
Briana
LikeLiked by 1 person
Awesome post! This is a very good place to start for a novice like me!
LikeLike