We will focus on POS tagging in this blog.
Notations
While HMM gives us a joint probability on tags and words: ![p({t}_{[1:n]},{w}_{[1:n]})](https://s0.wp.com/latex.php?latex=p%28%7Bt%7D_%7B%5B1%3An%5D%7D%2C%7Bw%7D_%7B%5B1%3An%5D%7D%29&bg=FFFFFF&fg=222222&s=0&c=20201002)
We will need an log-linear model to define ![p({t}_{[1:n]}|{w}_{[1:n]})](https://s0.wp.com/latex.php?latex=p%28%7Bt%7D_%7B%5B1%3An%5D%7D%7C%7Bw%7D_%7B%5B1%3An%5D%7D%29&bg=FFFFFF&fg=222222&s=0&c=20201002)
So our goal is to find the most likely tag sequence given word sequence W:
![{ t }_{ [1:n] }^{ * }={ argmax }_{ { t }_{ [1:n] } }p({ t }_{ [1:n] }|{ w }_{ [1:n] })](https://s0.wp.com/latex.php?latex=%7B+t+%7D_%7B+%5B1%3An%5D+%7D%5E%7B+%2A+%7D%3D%7B+argmax+%7D_%7B+%7B+t+%7D_%7B+%5B1%3An%5D+%7D+%7Dp%28%7B+t+%7D_%7B+%5B1%3An%5D+%7D%7C%7B+w+%7D_%7B+%5B1%3An%5D+%7D%29&bg=FFFFFF&fg=222222&s=0&c=20201002)
The trigram Log-Linear Tagger is given below:

The first line is simply a chain rule, which conditions on word from the start to the current, and tags from the start to the previous one. The second line applies the independence assumptions, because it is a trigram model, so we condition on only previous two tags, not every tag in the history.
Histories
We will define a 4-tuple representation as the history: ![({t}_{-2},{t}_{-1},{w}_{[1:n]},i)](https://s0.wp.com/latex.php?latex=%28%7Bt%7D_%7B-2%7D%2C%7Bt%7D_%7B-1%7D%2C%7Bw%7D_%7B%5B1%3An%5D%7D%2Ci%29&bg=FFFFFF&fg=222222&s=0&c=20201002)
Here is the example.

Besides, we have a large set of all possible histories. Because you will have a number of different sentence length n, although the tag set is finite.
Feature Vectors
A feature here, means a mapping function f, who maps input domain (

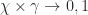
Here are two features we will use in the implementation:

There is a trigram feature, and it is very similar to the trigram model. Another one is a tag feature, it is actually mapping a word to a tag. It is from language model.
Say we have a labeled sentence: Characteristics \O of \O lipase \I-GENE.., we have now 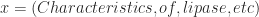
Besides, we will have a weight vector 
GEN Function
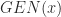

![{t}_{[1:n]}](https://s0.wp.com/latex.php?latex=%7Bt%7D_%7B%5B1%3An%5D%7D&bg=FFFFFF&fg=222222&s=0&c=20201002)
Decoding
Now we have everything, and the decoding problem is given bellow:
 We can use the Viterbi algorithm to find out the maximum local score
We can use the Viterbi algorithm to find out the maximum local score 

Implementation
The data is described in this blog. Full data and code find here. We are using the same dataset on tagging these words. My code is missing the q function, thus the ViterbiGLM is only pseudo code. But you will find the codes for getting bigram and tag features.
The

import sys
from collections import defaultdict
class decoder():
def __init__(self):
self.trigram = defaultdict(float)
self.tag = defaultdict(float)
def build_maps(self,infile):
for line in infile:
#TAG:photobleached:I-GENE -1.0
group = line.split(' ')
if group[0].split(':')[0]=='TAG':
self.tag[group[0]]=float(group[1])
elif group[0].split(':')[0]=='TRIGRAM':
self.trigram[group[0]]=float(group[1])
print (len(self.tag),len(self.trigram))
#print (self.tag)
def get_g(self,x,tags):
g_for_x = defaultdict(lambda : defaultdict(int))
trigram_values = defaultdict(float) #g trigram = 1 or 0
tag_values = defaultdict(float) #g tag = 1 or 0
history = defaultdict(tuple) # tupel of four <t-2,t-1,x,i>
#let's create the history
tags.insert(0,'*') #init
tags.insert(0,'*') #init
for i in range(0,len(x)):
history[i+1]=tuple((tags[i],tags[i+1],x))
#let's create the trigram_values and tag_values
#for each word
for i in range(0,len(x)):
#for all possible tags in y
y_current = ['O',' I-GENE']
if i == 0:
y_sub2 = y_sub1 = ['*']
elif i == 1:
y_sub2 = ['*']
y_sub1 = y_current
else:
y_sub2 = y_sub1 = y_current
for y_sub2_tag in y_sub2:
for y_sub1_tag in y_sub1:
for y_current_tag in y_current:
if y_sub2_tag == tags[i] and y_sub1_tag == tags[i+1] and y_current_tag == tags[i+2]:
trigram_values [tuple((y_sub2_tag,y_sub1_tag,y_current_tag,(i+1)))] = 1.
if y_current_tag == tags[i+2]:
tag_values [tuple((tags[i+2],x[i]))] = 1.
#get v * g
for i in range(0,len(x)):
trigram_list = ['TRIGRAM',history[i+1][0],history[i+1][1],tags[i+2]]
v_trigram = self.trigram[':'.join(trigram_list)]
now = tuple((history[i+1][0],history[i+1][1],tags[i+2],(i+1)))
g_tag = tag_values[tuple((tags[i+2],x[i]))]
tag_word_list = ['TAG',x[i],tags[i+2]]
v_tag = self.tag[':'.join(tag_word_list)]
score = trigram_values[now] * v_trigram + v_tag * g_tag
print ('position i:',i,';score:',score)
# pseudo code of ViterbiGLM
# q functon is missing 😦
def ViterbiGLM(self,v,g,x):
pi = defaultdict(float)
pi[tuple((0,'*','*'))] = 1.
for k in range(0,len(x)):
s = ['O',' I-GENE']
if i == 0:
s_sub2 = s_sub1 = ['*']
elif i == 1:
s_sub2 = ['*']
s_sub1 = s
else:
s_sub2 = s_sub1 = s
for u in s_sub1:
for v in s:
max_pi = []
for t in s_sub2:
max_pi.append(pi[tuple((k-1,t,u))] * q(v|t,u,w(1:n),k))
pi[tuple((k,u,v))] = max(max_pi)
# get tags here....
return tag_seq
def load_sentence(self, train_file):
sentence = []
tags = []
for line in train_file:
if len(line.strip().split(' ')) == 2:
line_list = line.strip().split(' ')
sentence.append(line_list[0])
tags.append(line_list[1])
elif len(line.strip()) == 0:
self.get_g(sentence,tags)
sentence.clear()
tags.clear()
def usage():
sys.stderr.write("""
Whatever...""")
if __name__ == "__main__":
decoder = decoder()
input_file = open (r'tag.model','r')
train_file = open (r'small_gene.train','r')
decoder.build_maps(input_file)
decoder.load_sentence(train_file)
#decoder.get_g()
print ('start')
Here are some sample outputs, showing a score of each tag in a particular position i. (A part of training)


your code have no indent~
LikeLike
haha sorry!
It is always not easy to edit code here lol
LikeLike