First, let’s see what is regularization from a simple example. Then we will have a look at some different types of loss functions.
Regularization
Reviewed the definition of regularization today from Andrew’s lecture videos.
You will probably have noticed that we had a regularizer in some of the loss functions. So what’s that for? It’s mainly for preventing the overfitting, especially when we have some prior knowledge. Take the house prices for the example:

To address overfitting, we can either reduce the number of features by manually select features, for example. Or we could use regularization, and it performs well when we have a number of features and each of them contributes little. We keep them all, but reduce the magnitude or number of parameters.
So we want to find the relations between size and price, given the size features as x, and parameters as 

The loss function we choose is 
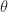


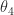
We times
In general, we can penalize other parameters, next is a regularized negative log-likelihood loss function:

![J(\theta )=-[\frac { 1 }{ m } \sum _{ i=i }^{ m }{ { y }^{ (i) }log{ h }_{ \theta } } ({ x }^{ (i) })+(1-{ y }^{ (i) })log(1-{ h }_{ \theta }({ x }^{ (i) }))] + \frac { \lambda }{ 2m } \sum _{ i=1 }^{ m }{ { { \theta }_{ j } }^{ 2 } }](https://s0.wp.com/latex.php?latex=J%28%5Ctheta+%29%3D-%5B%5Cfrac+%7B+1+%7D%7B+m+%7D+%5Csum+_%7B+i%3Di+%7D%5E%7B+m+%7D%7B+%7B+y+%7D%5E%7B+%28i%29+%7Dlog%7B+h+%7D_%7B+%5Ctheta+%7D+%7D+%28%7B+x+%7D%5E%7B+%28i%29+%7D%29%2B%281-%7B+y+%7D%5E%7B+%28i%29+%7D%29log%281-%7B+h+%7D_%7B+%5Ctheta+%7D%28%7B+x+%7D%5E%7B+%28i%29+%7D%29%29%5D+%2B+%5Cfrac+%7B+%5Clambda+%7D%7B+2m+%7D+%5Csum+_%7B+i%3D1+%7D%5E%7B+m+%7D%7B+%7B+%7B+%5Ctheta+%7D_%7B+j+%7D+%7D%5E%7B+2+%7D+%7D+&bg=FFFFFF&fg=222222&s=0&c=20201002)
So the 
Loss Functions
Let’s forget about the regularization for a moment, and go through some standard loss functions.
Energy Loss
The energy loss is straightforward but only works when pushing down Energies.
![]()
It is popular among regression and neural network training.
Generalized Perceptron Loss
Similarly, we give the definition below:
![]()
We minus the minimum value (lower bound) of the energy loss, which makes the perception loss to be positive.
Generalized Margin Losses
This type contains a lot: hinge loss, LVQ2 loss, minimum classification error loss (MCE), square-square loss, square-exponential loss, etc. You have definitely seen some of them in general machine learning approaches . The main goal is to create an energy gap between the correct answer and the incorrect ones.
TBC..

One thought on “Deep Learning 12: Energy-Based Learning (2)–Regularization & Loss Functions”