In our daily life, we always repeating something mentioned before in our dialogue, like the name of people or organizations. “Hi, my name is Pikachu”, “Hi, Pikachu,…” There is a high probability that the word “Pikachu” will not be in the vocabulary extracted from the training data. So in the paper (Incorporating Copying Mechanism in Sequence-to-Sequence Learning), the authors proposed CopyNet which brings copying mechanism to seq2seq models with encoder and decoder structure. Read from my old post to learn the prerequisite knowledge.
Structure
Encoder: a bi-directional RNN is used. We define 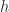


Note that we define a concatenation of vectors 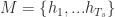

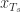

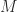

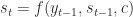
Decoder: we would get access to
Prediction
There are two ways to generate a word, naturally, to copy from the input sentence or to generate from a vocabulary. We define 

To generate a new word 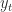

We define the two types of probabilities bellow:

where 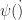
* is UNK
* is a word from vocabulary
* is a word from
* is a word from
Now we will define the scoring functions.
Generate-Mode When the word is from vocabulary

where 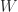
Copy-Mode We consider the case if the word is from the original input sentence:

In equation (6), we should sum up all the situations, because a word might have occurred multiple times in the input sentence.
Update States
We introduced the decoder states 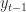
![[e(y_{t-1}),\xi(y_{t-1})]^T](https://s0.wp.com/latex.php?latex=%5Be%28y_%7Bt-1%7D%29%2C%5Cxi%28y_%7Bt-1%7D%29%5D%5ET&bg=FFFFFF&fg=222222&s=0&c=20201002)

The authors called the 

Experiments
Synthetic dataset In the paper they used some rules to construct a dataset of simple copying data, for example:
abcdxef-> cdxg
abydxef->xdig
Compared with the Enc-Dec and RNNSearch model, the CopyNet can have a competitive accuracy. (More details please check their paper.)
Summarization
An example result shows bellow.

The Chinese parts give the tokenization and the underline words are OOV. The highlighted words are the copied ones (where the probabilities are higher than generate-mode probabilities).

So while computing score_g (generate mode) vocabulary considered is vocabulary from entire training data or only the current batch
We need to create embedding for both oov word and vocab word right? because we give ids from word2index mapping as an input to the encoder and thus we create an embedding layer of size vocab_size X emd_size where vocab_size is for the entire training data. the paper uses the term instance vocabulary but I am not sure which vocab_size is used for computing score_g and score_c.
LikeLike
Replied your email just now….
LikeLike