Variational Auto-Encoders
My post about Auto-encoder.
For Variational Auto-Encoders (VAE) (from paper Auto-Encoding Variational Bayes), we actually add latent variables to the existing Autoencoders. The main idea is, we want to restrict the parameters from a known distribution. Why we want this? We wish the generative model to provide more “creative” things. If the model only sees the trained samples, it will eventually lose the ability to “create” more! So we add some “noises” to the parameters by forcing the parameters to adapt to a known distribution.

As shown in the above picture, in the encoder part, things are more complex than the original Autoencoders. We keep the decoder to be the same with that of Autoencoders. The goal is to let the hidden representation 


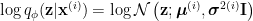
In fact, if we force 
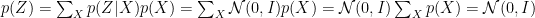
When we have a input 





Variational Graph Auto-Encoders (VGAE)
The post about Graph Convolutional Networks.
As you may have guessed from the title, the input will be the whole graph, and the output will be a reconstructed graph. Let us formulate the task. The adjacency matrix is defined as A, and the node feature matrix is X. At the same time, Z is the hidden variables. Here we are going to show the model that only reconstruct the adjacency matrix which has the information about the graph structure.

Inference Step (or encoding) In the paper, you can see the author actually provided different names rather than encode and decode. The first step is to do inference to get latent variables Z. From the previous section, we know that the encoder will generate the mean vector

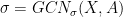

Similarly, for each input i we want:

Generative Model (or decoding) After getting Z, we will reconstruct 
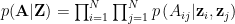

Learning The loss function during learning will be two parts: constructing loss and the latent variable restriction loss. Constructing loss is to see if the constructed adjacency matrix is similar to the input one; the other loss is to apply KL-divergence to measure how similar the distribution of the latent variable and a normal distribution.
![\mathcal { L } = \mathbb { E } _ { q ( \mathbf { Z } | \mathbf { X } , \mathbf { A } ) } [ \log p ( \mathbf { A } | \mathbf { Z } ) ] - \mathrm { KL } [ q ( \mathbf { Z } | \mathbf { X } , \mathbf { A } ) \| p ( \mathbf { Z } ) ]](https://s0.wp.com/latex.php?latex=%5Cmathcal+%7B+L+%7D+%3D+%5Cmathbb+%7B+E+%7D+_+%7B+q+%28+%5Cmathbf+%7B+Z+%7D+%7C+%5Cmathbf+%7B+X+%7D+%2C+%5Cmathbf+%7B+A+%7D+%29+%7D+%5B+%5Clog+p+%28+%5Cmathbf+%7B+A+%7D+%7C+%5Cmathbf+%7B+Z+%7D+%29+%5D+-+%5Cmathrm+%7B+KL+%7D+%5B+q+%28+%5Cmathbf+%7B+Z+%7D+%7C+%5Cmathbf+%7B+X+%7D+%2C+%5Cmathbf+%7B+A+%7D+%29+%5C%7C+p+%28+%5Cmathbf+%7B+Z+%7D+%29+%5D&bg=ffffff&fg=000000&s=0&c=20201002)
Here we have 
Graph Auto-Encoders (GAE)
For a simple GAE, we will get rid of the distribution restrictions, simply take a GCN as the encoder and an inner product function as the decoder:
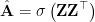
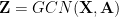
References
https://zhuanlan.zhihu.com/p/34998569 (Chinese)
https://arxiv.org/abs/1312.6114
https://arxiv.org/pdf/1611.07308.pdf

i am not a cs major student but I like your blog!
LikeLike
thank you
LikeLike